Hello everyone! We are very pleased to have Agathe Balayn showcase her upcoming CHI 2023 paper with us, titled “Faulty or Ready? Handling Failures in Deep-Learning Computer Vision Models until Deployment: A Study of Practices, Challenges, and Needs.“.
[Reading time: 5 min.]

What’s your name?
Hi, my name is Agathe Balayn.
Citation:
Agathe Balayn, Natasa Rikalo, Jie Yang, and Alessandro Bozzon. 2023. Faulty or Ready? Handling Failures in Deep-Learning Computer Vision Models until Deployment: A Study of Practices, Challenges, and Needs. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23), April 23–28, 2023, Hamburg, Germany. ACM, New York, NY, USA, 20 pages. https://doi.org/10.1145/3544548.3581555
TL;DR (if you had to describe this work in one sentence, what would you tell someone?):
Taking a step back from the technical development of algorithmic, explainability, methods for the future debugging of a machine learning model, we investigate current debugging practices: how do machine learning developers currently debug their models, what are the challenges they really face, and what are their true needs?
What problem is this research addressing, and why does it matter?
While many research efforts are put into developing explainability methods for machine learning models, it remains challenging for practitioners to develop models that are trustworthy (testified by accidents and social harms caused by such models). We investigate practices and needs of model developers, and misalignments between research and practice, to propose future research directions.
How did you approach this problem?
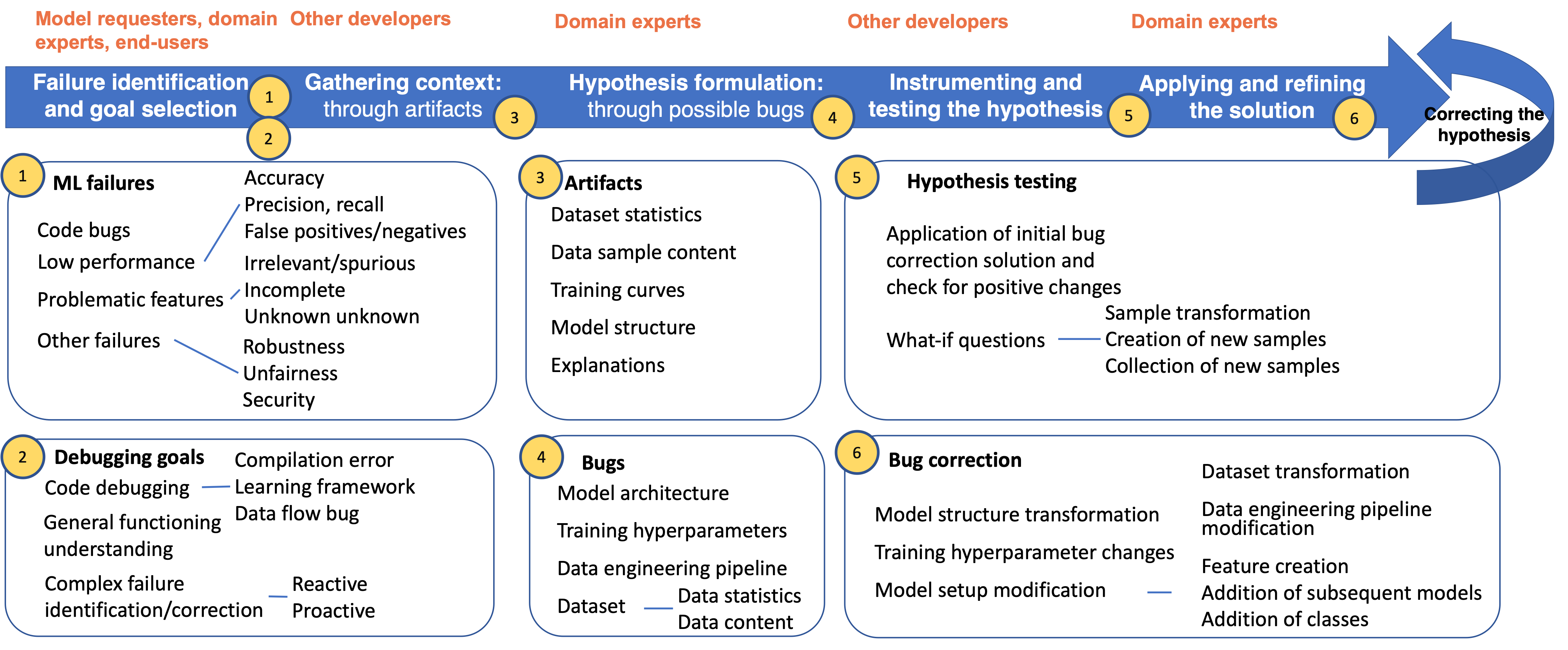
After investigating what current research literature tells us about machine learning debugging practices (almost nothing, especially for computer vision), and about potential solutions for debugging (among which are well-known explainability methods), we conducted a qualitative study. We performed semi-structured interviews with 18 developers of various backgrounds and machine learning experience. We presented them with a task where they have to investigate a model, declare it ready for deployment or debug it. We prompted them to speak aloud to understand how they would tackle the debugging task. We then analyzed their debugging stages, methods they might use, challenges they face, and limitations.

What were your key findings?
While practices broadly follow the traditional software debugging workflow, they differentiate by the ambiguous way the model requirements are defined, by the type of hypothesis formulation and instrumentation activities performed, by the artifacts employed to facilitate the workflow, and by the fluidity of the relevant concepts.
Debugging workflows are typically performed manually and collaboratively, without resorting to methods developed specifically for machine learning models. There, practitioners tend to have a narrow understanding of the bugs that any machine learning model might suffer from, skewed by their prior experience.
These results bear implications for debugging tool design and machine learning education.
What is the main message you’d like people to take away?
The machine learning community is primarily focusing on the development of algorithmic tools that could potentially be used for model debugging. Yet, it is also important to acknowledge the socio-technical nature of machine learning, introduce design methods to research, and study practices, practitioners’ challenges, and their use of proposed tools.
What led / inspired you to carry out this research?
The few earlier works that have investigated practices in machine learning had triggered my interest in the topic. The proposed Critical Technical Practice by Phil Agre and trickling down/bubbling up ideas in HCI were also motivations for my work, as they made me reflect about the current research/practice gap in machine learning.
What kind of skills / background would you say one needs to perform this type of research?
I think one needs to be interested in interdisciplinary research.
One needs a good understanding of the technical machine learning literature, especially in terms of current proposed solutions for debugging, to compare current research directions to challenges faced by practitioners.
They also need knowledge and practice of qualitative, empirical, research methodologies in order to set up the semi-structured interviews and analyze them.
(Oftentimes, in computer science, we only learn about the first, but I believe that someone motivated by this research can also learn the second). We also need a lot of motivation to recruit the participants!
Any further reading you recommend?
- Agathe Balayn, Natasa Rikalo, Christoph Lofi, Jie Yang, and Alessandro Bozzon. 2022. How can Explainability Methods be Used to Support Bug Identification in Computer Vision Models? In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 184, 1–16. https://doi-org.tudelft.idm.oclc.org/10.1145/3491102.3517474
- Q. Vera Liao, Daniel Gruen, and Sarah Miller. 2020. Questioning the AI: Informing Design Practices for Explainable AI User Experiences. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–15. https://doi-org.tudelft.idm.oclc.org/10.1145/3313831.3376590
Your biography
I am a PhD candidate in Computer Science at Delft University of Technology. My research focuses on characterizing theories and practices for developing and evaluating machine learning models with regard to safety issues and societal harms, and on proposing supporting methods, user-interfaces, and workflows.
Although I was primarily trained in computer science, all along my PhD, I have learned about and used qualitative methods to conduct my research, as I believe socio-technical work is extremely needed for machine learning nowadays.
I’m finishing my PhD next month, and currently open to new research opportunities, so I would be very happy to discuss more with anyone interested in machine learning + HCI topics!
Follow me on Twitter 😊.
Agathe’s website: https://agathe-balayn.github.io/
CHI NL Read is a regular feature on the CHI NL blog, where board members and blog editors Lisa and Abdo invite a member of CHI NL to showcase a recent research paper they published to the wider SIGCHI community and world 🌍. One of the ideas behind CHI NL Read is to make research a bit more accessible to those outside of academic HCI.
✨ Get updates about HCI activities in the Netherlands ✨

CHI Nederland (CHI NL) is celebrating its 25th year anniversary this year, and we have much in store to acknowledge this occasion. Stay tuned!